文章目录
- 1、Collection
- 1.1 iterator 迭代器
- 2、List 有序集合
- 2.1 ArrayList ⭐
- 2.2 LinkedList
- 2.3 Queue
- 3、Set 无序集合
- 3.1 HashSet ⭐
- 3.2 TreeSet
- 3.3 LinkedHashSet
- 4、Map 键值集合
- 4.1 HashMap ⭐
- 4.2 TreeMap / LinkedHashMap
- 5、工具类
- 5.1 Collections
- 5.2 Arrays
- 【拓展】
- HashTable/ConcurrentHashMap
- 深入学习:吃透Java集合框架!
- 简易知识体系:
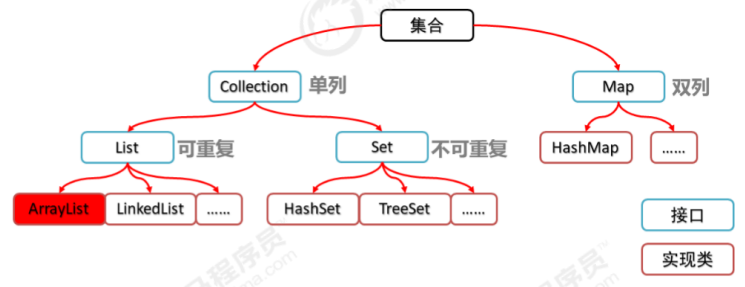
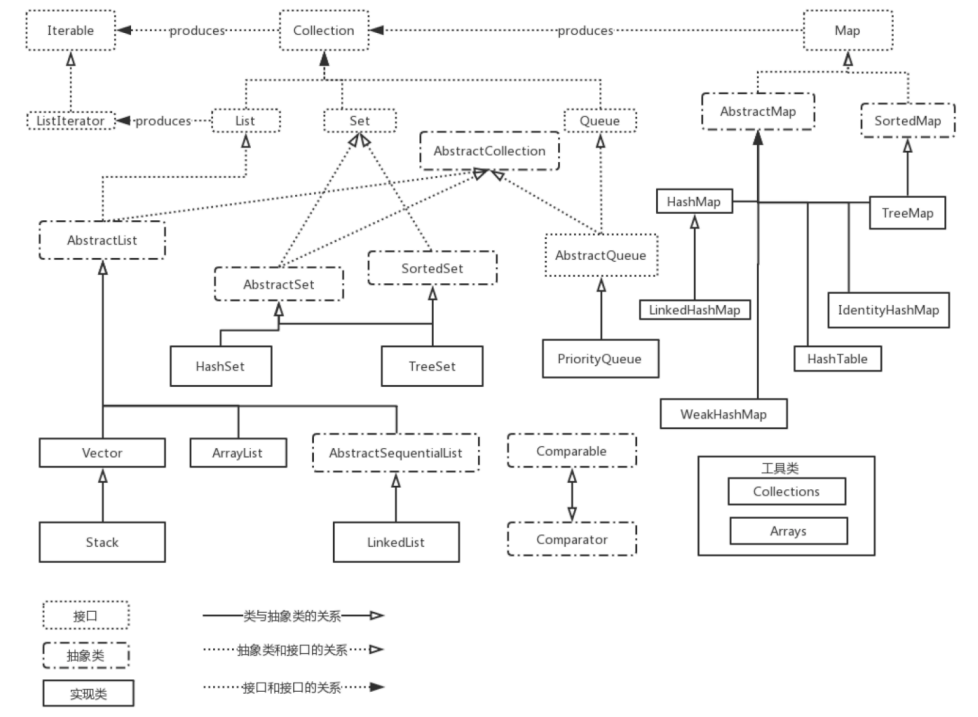
- 超详细体系架构图:
1、Collection
- Collection集合概述
- 是单例集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素
- JDK 不提供此接口的任何直接实现,它提供更具体的子接口(如Set和List)实现
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean | add(E e) | 添加元素 |
| boolean | remove(Object o) | 从集合中移除指定的元素 |
| void | clear() | 清空集合中的元素 |
| boolean | contains(Object o) | 判断集合中是否存在指定的元素 |
| boolean | isEmpty() | 判断集合是否为空 |
| int | size() | 集合的长度,也就是集合中元素的个数 |
//创建Collection集合的对象
Collection<String> c = new ArrayList<String>();
//添加元素:boolean add(E e)
c.add("hello");
c.add("world");
1.1 iterator 迭代器
- 迭代器:集合的专用遍历方式
- Iterator iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
- 迭代器是通过**集合的iterator()**方法得到的,所以我们说它是依赖于集合而存在的
- 注:一共就这四个方法:
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean | hasNext() | 如果集合中存在元素,则返回true |
| E | next() | 返回集合的下一个元素 |
| void | remove() | 删除next()返回的最后一个元素 |
| void | forEachRemaining() | 对集合的每个剩余元素执行指定的操作 |
List<Integer> num = Arrays.asList(1, 2, 3); //创建一个ArrayList
ArrayList<Integer> nums = new ArrayList<>(num);
Iterator<Integer> iterate = nums.iterator(); //创建Iterator的实例
int number = iterate.next(); //1、使用next()方法
iterate.remove(); //2、使用remove()方法
while(iterate.hasNext()) { //3、使用hasNext()方法
//4、使用forEachRemaining()方法
iterate.forEachRemaining((value) -> System.out.print(value + ", "));
}
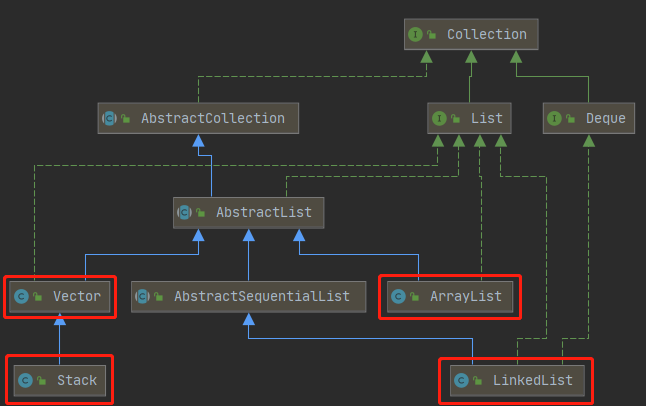
2、List 有序集合
- 概述:有序集合(序列),用户可以精确控制列表中每个元素的插入位置。用户可以通过整数索引访问元素,并搜索列表中的元素。
- List集合特点:有索引、允许重复的元素、元素存取有序
| 返回值 | 方法名 | 解释 |
|---|---|---|
| void | add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E | remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E | set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E | get(int index) | 返回指定索引处的元素 |
列表迭代器
- ListIterator介绍
- 通过List集合的listIterator()方法得到,所以说它是List集合特有的迭代器
- 用于允许程序员沿任一方向遍历的列表迭代器,在迭代期间修改列表,并获取列表中迭代器的当前位置
List<String> list = new ArrayList<String>(); //创建集合对象
list.add("hello"); //添加元素
list.add("world");
ListIterator<String> lit = list.listIterator(); //获取列表迭代器
while (lit.hasNext()) {
String s = lit.next();
if(s.equals("world")) lit.add("javaee");
}
2.1 ArrayList ⭐
- ArrayList:底层是数组结构实现,查询快、增删慢 (底层:动态数组)
- 泛型的使用:约束集合中存储元素的数据类型
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean
void | add(E element)
add(int index, E element) | 将指定元素追加到ArrayList的末尾
在指定位置插入指定元素 |
| boolean
E | remove(Object element)
remove(int index) | 从ArrayList中移除指定元素
移除指定位置的元素 |
| E | get(int index) | 获取指定位置的元素 |
| E | set(int index, E element) | 将指定位置的元素替换为新元素,
并返回原来位置元素的值。 |
//创建ArrayList集合对象
ArrayList<Student> array = new ArrayList<Student>();
Student s1 = new Student("林青霞", 30);
Student s2 = new Student("张曼玉", 35);
array.add(s1);
array.add(s2);
//迭代器:集合特有的遍历方式
Iterator<Student> it = array.iterator();
while (it.hasNext()) {
Student s = it.next();
System.out.println(s.getName() + "," + s.getAge());
}
//普通for:带有索引的遍历方式
for(int i=0; i<array.size(); i++) {
Student s = array.get(i);
System.out.println(s.getName() + "," + s.getAge());
}
//增强for:最方便的遍历方式
for(Student s : array) {
System.out.println(s.getName() + "," + s.getAge());
}
:::tips
- 增加(add)操作:在末尾添加元素的时间复杂度为O(1),如果需要在中间或开头插入元素,则为O(n)。
- 删除(remove)操作:删除指定索引的元素的时间复杂度为O(n),因为需要移动后续元素。
- 修改(set)操作:修改指定索引位置的元素的时间复杂度为O(1)。
- 查找(get)操作:根据索引获取元素的时间复杂度为O(1)。
:::
2.2 LinkedList
- LinkedList:底层是链表结构实现,查询慢,增删快(底层:双向链表)
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean
void
boolean | add(E element)
add(int index, E element)
addFirst(E element) | 元素插入到链表末尾
指定位置插入元素
在链表开头插入元素(addLast) |
| E
boolean
E | remove(int index)
remove(E element)
removeFirst() | 移除指定位置的元素,并返回被移除的元素
从链表中移除指定元素
移除并返回链表第一个元素(removeLast) |
| E
void | get(int index)
getFirst() | 获取指定位置的元素,并返回其值。
返回链表的第一个元素(getLast) |
| E | set(int index, E element) | 将指定位置的元素替换为新元素,并返回原来位置元素的值。 |
:::tips
- 增加(add)操作:在末尾添加元素的时间复杂度为O(1),如果需要在中间或开头插入元素,则为O(n)。
- 删除(remove)操作:删除指定节点的时间复杂度为O(1)。
- 修改(set)操作:修改指定节点的元素的时间复杂度为O(1)。
- 查找(get)操作:根据索引获取元素的时间复杂度为O(n)。
:::
2.3 Queue
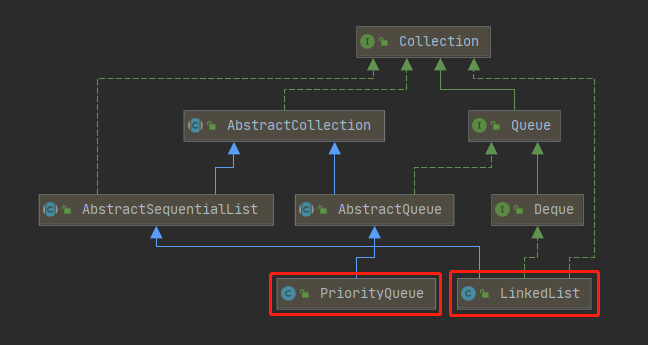
1、PriorityQueue
| 返回值 | 方法名 | 解释 |
|---|---|---|
| boolean | offer(E e) | |
| add(E e) | 都是插入到优先级队列中 | |
| 差别:队列已满时,offer返回false;add抛出异常 | ||
| E | poll() | 检索并移除队列中的头部元素 |
| boolean | peek() | |
| element() | 检索但不移除队列中的头部元素 | |
| 差别:队列为空时,peek返回null;element抛出异常 | ||
| boolean | remove(Object o) | 移除队列中的指定元素 |
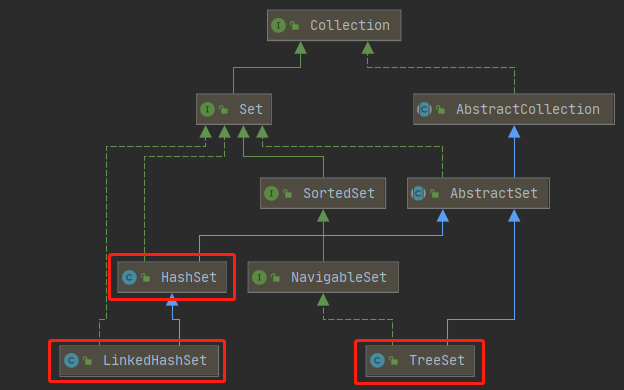
3、Set 无序集合
- Set集合的特点:元素存取无序、没有索引(只能迭代器/增强for循环遍历)、不能存储重复元素
哈希值
- Hash值:是JDK根据对象的地址/字符串/数字算出来的int类型的数值
- 如何获取哈希值:Object类中的public int hashCode():返回对象的哈希码值
- 哈希值的特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
3.1 HashSet ⭐
:::tips
HashSet集合特点:
-
底层数据结构是哈希表
-
对集合的迭代顺序不作任何保证,也就是说不保证存储和取出的元素顺序一致
-
没有带索引的方法,所以不能使用普通for循环遍历
-
由于是Set集合,所以是不包含重复元素的集合
:::
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean | add(E element)
addAll(Collection<? extends E> collection) | 将指定元素添加到HashSet中 将指定集合中所有元素添加到HashSet中 | | boolean | remove(Object element) removeAll(Collection<?> collection) | 从HashSet中移除指定元素
从HashSet中移除与指定集合中元素相同的所有元素 |
| boolean | retainAll(Collection<?> collection) | 仅保留HashSet中与指定集合中元素相同的元素,移除其他元素。 | | boolean | containsAll(Collection<?> collection) | 判断HashSet是否包含指定集合中的所有元素 | -
哈希表图示:**数组+链表 **结构
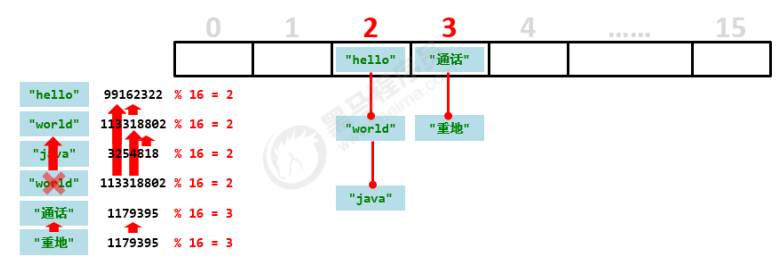
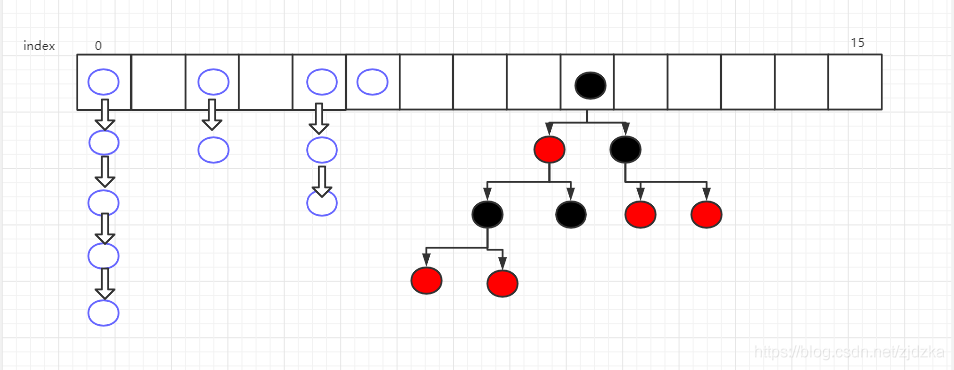
-
当链表元素>=8时,链表进化成红黑树(增删慢,要维护树结构,但查询效率高!)
:::tips -
增加(add)操作:添加元素的时间复杂度为O(1)。
-
删除(remove)操作:删除元素的时间复杂度为O(1)。
-
修改(set)操作:HashSet不提供直接修改操作,需要先删除再添加。
-
查找(contains)操作:判断元素是否存在的时间复杂度为O(1)。
:::
3.2 TreeSet
-
TreeSet:元素有序,可以按照一定的规则进行排序,具体排序方式取决于构造方法
| 构造方法 | 解释 |
| — | — |
| TreeSet() | 根据其元素的自然排序进行排序 |
| TreeSet(Comparator comparator) | 根据指定的比较器进行排序 | -
TreeSet特点:没有索引方法(不能使用普通for循环遍历)、Set集合(不包含重复元素集合)
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean | add(E element) | 将指定元素添加到TreeSet中 |
| boolean | remove(Object element) | 从TreeSet中移除指定元素 |
| E | first()
last() | 返回TreeSet中的第一个(最小)元素。
返回TreeSet中的最后一个(最大)元素。 |
| E | ceiling(E element)
floor(E element) | 返回TreeSet中大于等于给定元素的最小元素。
返回TreeSet中小于等于给定元素的最大元素。 |
| E | pollFirst()
pollLast() | 移除并返回TreeSet中的第一个(最小)元素。
移除并返回TreeSet中的最后一个(最大)元素。 |
| NavigableSet | descendingSet() | 返回TreeSet的逆序视图,其中元素按降序排列。 |
:::tips
- 增加(add)操作:添加元素的时间复杂度为O(log n)。
- 删除(remove)操作:删除元素的时间复杂度为O(log n)。
- 修改(set)操作:TreeSet不提供直接修改操作,需要先删除再添加。
- 查找(contains)操作:判断元素是否存在的时间复杂度为O(log n)。
:::
自然排序Comparable / 比较器排序Comparator
- 案例需求
- 存储学生对象并遍历,创建TreeSet集合使用无参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
- 实现步骤
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
:::tips
- 自然排序Comparable的使用:
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
:::
//自然排序 Comparator
TreeSet<Student> ts = new TreeSet<Student>();
:::tips
- 比较器排序Comparator的使用:
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
:::
//比较器 Comparable
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int num = s1.getAge() - s2.getAge(); //主要条件
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()):num; //次要条件
return num2;
}
});
3.3 LinkedHashSet
- LinkedHashSet集合特点
- 哈希表和链表实现的Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素唯一,也就是说没有重复的元素
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean | add(E element) | 将指定元素添加到LinkedHashSet中 |
| boolean | remove(Object element) | 从LinkedHashSet中移除指定元素 |
| E | get(int index) | 根据索引位置获取LinkedHashSet中的元素。 |
| Iterator | iterator() | 遍历LinkedHashSet中的元素 |
| Object[] | toArray() | 将LinkedHashSet转换为一个对象数组 |
| boolean | addAll(Collection<? extends E> collection) | 将指定集合中的所有元素添加到LinkedHashSet中 | | boolean | retainAll(Collection<?> collection) | 仅保留LinkedHashSet中与指定集合中的元素相同的元素,移除其他元素。 |
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<String>();
//添加元素
linkedHashSet.add("hello");
linkedHashSet.add("world");
for(String s : linkedHashSet)
System.out.println(s);
4、Map 键值集合
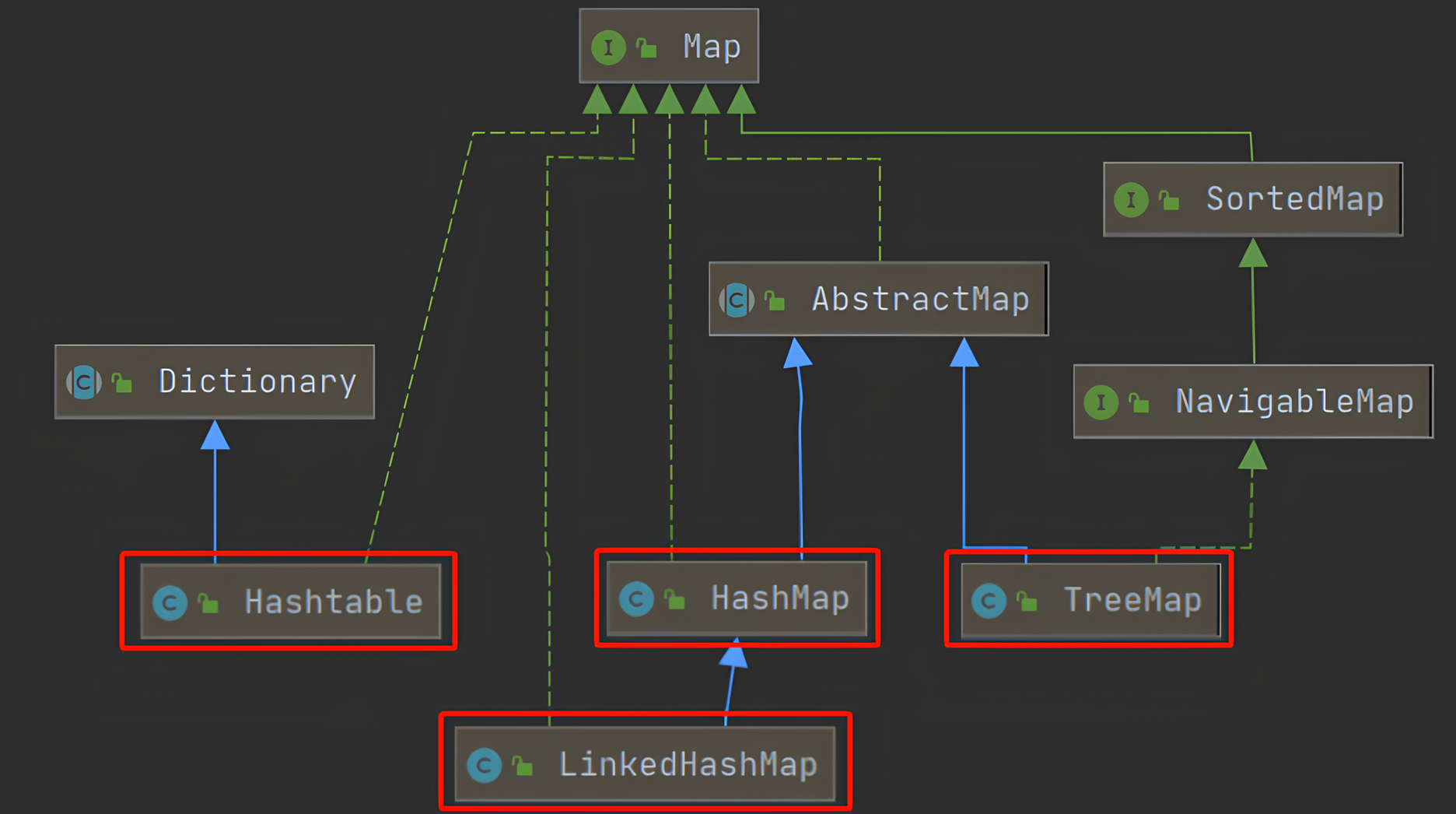
- Map集合特点 :key:value对映射关系、键不能重复,值可以重复、元素存取无序
4.1 HashMap ⭐
:::tips
**概述:**HashMap使用哈希表来存储数据,通过计算键的哈希值来确定其在内部数组中的存储位置。
- HashMap的键是唯一的,如果插入相同的键,新的值会覆盖旧的值。它不保证键值对的顺序,也不保证插入顺序和访问顺序一致。
- 使用HashMap可以快速地插入、获取、更新和删除键值对,其时间复杂度为O(1)。它是线程不安全的,需要在多线程环境下使用可以使用ConcurrentHashMap。
- HashMap在遍历时,不保证元素的顺序,如果需要有序遍历,可以考虑使用LinkedHashMap。此外,由于哈希碰撞的存在,当键的哈希值相同时,会使用链表或红黑树等数据结构来解决冲突,以保证性能。
:::
| 返回值 | 方法名 | 解释 |
| — | — | — |
| V | put(K key, V value) | 将指定的键值对添加到HashMap中【键存在:并返回之前关联的值 / 键不存在:则返回null】 |
| V | remove(Object key) | 移除HashMap中指定键对应的键值对,并返回之前关联的值。 |
| boolean | containsKey(Object key)
containsValue(Object value) | 判断HashMap中是否包含指定键 / 值。 |
- 集合的获取功能
| 返回值 | 方法名 | 解释 |
| — | — | — |
| V | get(Object key) | 根据键获取值 |
| Set | keySet() | 获取所有键的集合 |
| Collection | values() | 获取所有值的集合 |
| Set | entrySet() | 获取所有键值对对象的集合 |
Map<String, String> map = new HashMap<String, String>();
map.put("张无忌", "赵敏");
map.put("郭靖", "黄蓉");
//V get(Object key):根据键获取值
System.out.println(map.get("张无忌"));
System.out.println(map.get("张三丰"));
//Set<K> keySet():获取所有键的集合
Set<String> keySet = map.keySet();
for(String key : keySet)
String value = map.get(key); //获得到value
//Collection<V> values():获取所有值的集合
Collection<String> values = map.values();
for(String value : values)
System.out.println(value);
:::tips
- 增加(put)操作:添加键值对的时间复杂度为O(1)。
- 删除(remove)操作:删除键值对的时间复杂度为O(1)。
- 修改(put)操作:修改键值对的时间复杂度为O(1)。
- 查找(get)操作:根据键获取值的时间复杂度为O(1)。
:::
1、String值是Student
HashMap<String, Student> hm = new HashMap<String, Student>();
Student s1 = new Student("林青霞", 30);
Student s2 = new Student("张曼玉", 35);
hm.put("itheima001", s1);
hm.put("itheima002", s2);
//方式1:键找值
Set<String> keySet = hm.keySet();
for (String key : keySet) {
Student value = hm.get(key);
System.out.println(key + "," + value.getName() + "," + value.getAge());
}
//方式2:键值对对象找键和值
Set<Map.Entry<String, Student>> entrySet = hm.entrySet();
for (Map.Entry<String, Student> me : entrySet) {
String key = me.getKey();
Student value = me.getValue();
System.out.println(key + "," + value.getName() + "," + value.getAge());
}
2、Student值是String
HashMap<Student, String> hm = new HashMap<Student, String>();
Student s1 = new Student("林青霞", 30);
Student s2 = new Student("张曼玉", 35);
hm.put(s1, "西安");
hm.put(s2, "武汉");
Set<Student> keySet = hm.keySet();
for (Student key : keySet) {
String value = hm.get(key);
System.out.println(key.getName() + "," + key.getAge() + "," +
value);
}
4.2 TreeMap / LinkedHashMap
-
TreeMap:
| 返回值 | 方法名 | 解释 |
| — | — | — |
| K | firstKey()
lastKey() | 返回TreeMap中最小的键
返回TreeMap中最大的键 |
| K | higherKey(K key)
lowerKey(K key) | 返回TreeMap中严格大于给定键的最小键;
返回TreeMap中严格小于给定键的最大键; |
| K | ceilingKey(K key)
floorKey(K key) | 返回TreeMap中大于或等于给定键的最小键;
返回TreeMap中小于或等于给定键的最大键; |
| Map.Entry<K, V> | pollFirstEntry()
pollLastEntry() | 移除并返回TreeMap中最小的键值对
移除并返回TreeMap中最大的键值对 | -
LinkedHashMap:
| 返回值 | 方法名 | 解释 |
| — | — | — |
| boolean | removeEldestEntry(Map.Entry<K, V> eldest) | 在插入新的键值对之后,判断是否需要移除最老的键值对。默认实现为始终返回false,即不移除最老的键值对。如果需要实现移除策略,可以重写该方法。 |
:::tips
- 增加(put)操作:添加键值对的时间复杂度为O(log n)。
- 删除(remove)操作:删除键值对的时间复杂度为O(log n)。
- 修改(put)操作:修改键值对的时间复杂度为O(log n)。
- 查找(get)操作:根据键获取值的时间复杂度为O(log n)。
:::
5、工具类
- 工具类设计思想
- 构造方法用private修饰
- 成员用public static修饰
5.1 Collections
1、Collections概述和使用
- Collections类的作用
是针对集合操作的工具类 - Collections类常用方法
| 方法名 | 说明 |
| — | — |
| public static void sort(List list) | 升序 |
| public static void reverse(List list) | 反转 |
| public static void shuffle(List list) | 随机排序 |
Collections.sort(list);
Collections.reverse(list);
Collections.shuffle(list);
- 详细方法:
| 返回值 | 方法名 | 解释 |
| — | — | — |
| void | sort(list) | 对指定的List升序排序,
要求元素的类型实现Comparable接口 |
| void | reverse(list) | 反转指定List中元素的顺序 |
| int | binarySearch(list, key) | 使用二分查找算法查找已排序List指定的关键字。返回关键字在List中的索引,如果找不到则返回负数 |
| void | shuffle(list) | 随机排列指定List中的元素 |
| boolean | addAll(collection, elements) | 将指定元素添加到指定Collection中。
如果Collection发生改变,则返回true。 |
| T | max(collection)
min(collection) | 返回集合中的最大/最小元素 |
| int | frequency(collection, object) | 返回指定对象在指定
Collection中出现的次数 |
| Object[] | toArray(collection) | 将指定Collection转换为数组 |
| Collection | synchronizedCollection(collection) | 返回指定Collection的同步
(线程安全)版本 |
5.2 Arrays
-
Arrays的常用方法
| 方法名 | 说明 |
| — | — |
| public static String toString(int[] a) | 返回指定数组的内容的字符串表达形式 |
| public static void sort(int[] a) | 按照数字顺序排列指定的数组 |
| public static List<?> asList(?) | 将对象数组转为List集合 | -
详细方法
| 返回值 | 方法名 | 解释 |
| — | — | — |
| String | toString(array) | 将指定数组转换为字符串表示形式。返回的字符串包含数组的元素,以逗号分隔,并使用方括号括起来。 |
| List | asList(array) | 将数组转换为List集合 |
| Stream | stream(array) | 将数组转换为流(Stream)对象,
可以进行各种流操作。 |
| void | sort(array) | 对数组进行升序排序。要求数组元素的类型实现Comparable接口。 |
| int | binarySearch(array, key) | 返回栈顶的元素,但不移除它 |
| T[] | copyOf(original, newLength) | 对集合的每个剩余元素执行指定的操作 |
| void | fill(array, value) | 将指定值填充到数组的每个元素中 |
| int | hashCode(array) | 返回指定数组的哈希码值 |
【拓展】
HashTable/ConcurrentHashMap
- 集合体系架构图:
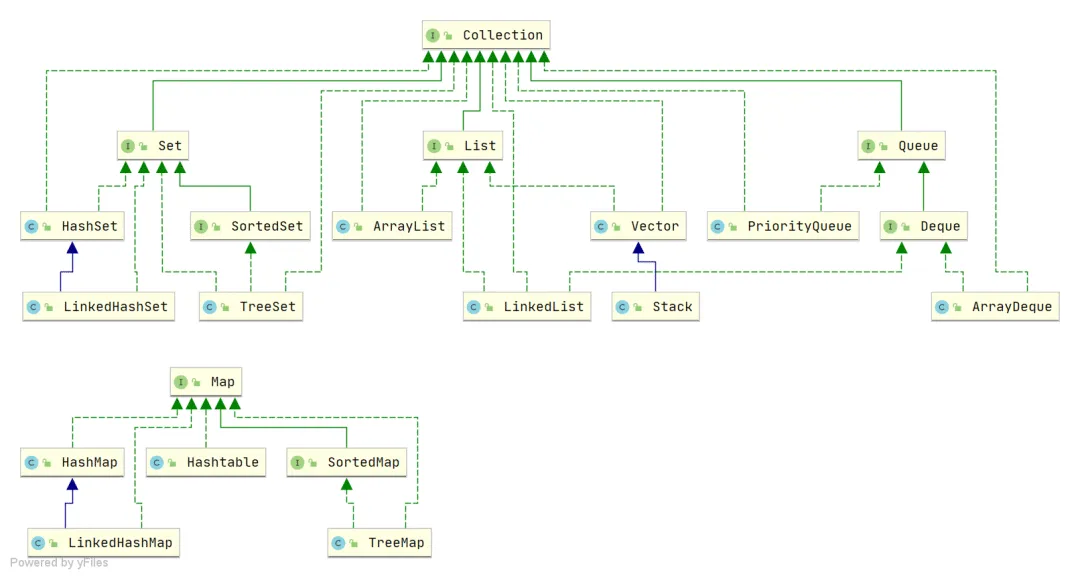
- HashTable存储发生哈希碰撞:
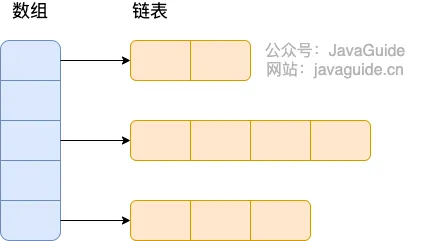
- ConcurrentHashMap存储发生哈希碰撞:
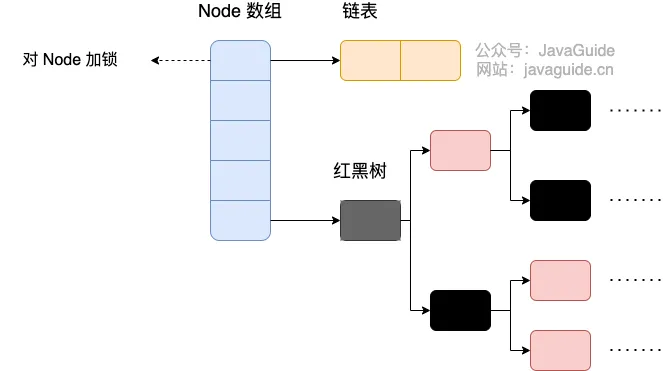
当冲突链表达到一定长度时,链表会转换成红黑树。